11月3日消息,美团曾于9月1日正式推出LongCat-Flash系列模型,目前已开源LongCat-Flash-Chat与LongCat-Flash-Thinking两个版本,受到了开发者的关注。而在今日,LongCat-Flash系列迎来了新的家族成员——LongCat-Flash-Omni的正式发布。
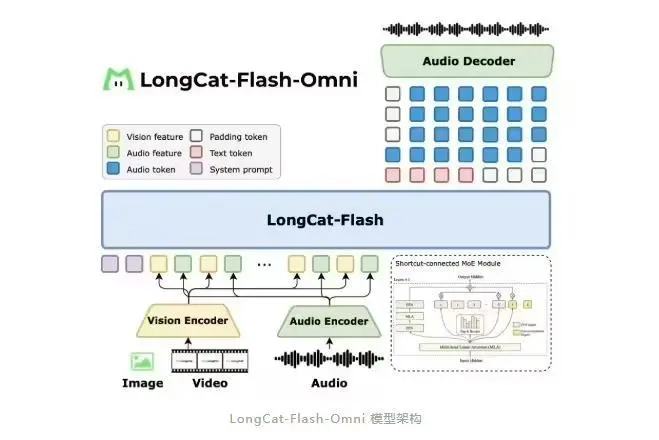
IT之家从官方介绍了解到,LongCat-Flash-Omni 依托 LongCat-Flash 系列的高效架构设计(即 Shortcut-Connected MoE,包含零计算专家),并且创新性地整合了高效多模态感知模块与语音重建模块。即便其总参数达到 5600 亿(激活参数为 270 亿)的庞大规模,依然具备低延迟的实时音视频交互能力,能为开发者的多模态应用场景提供更高效的技术方案。


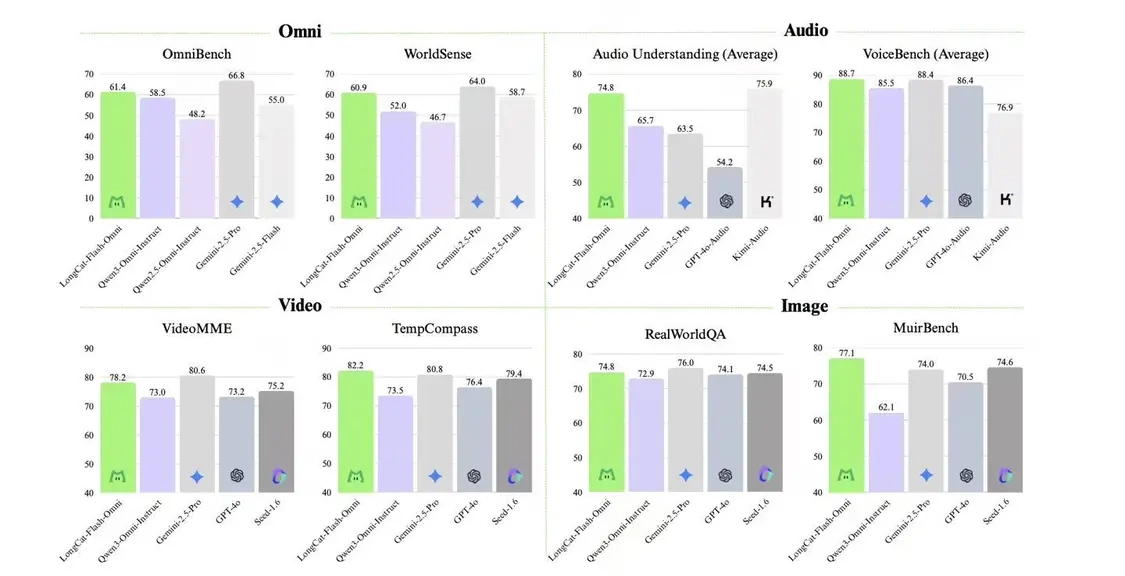
综合评估结果显示,LongCat-Flash-Omni 在全模态基准测试中处于开源领域的最先进水平(SOTA),并且在文本、图像、视频理解以及语音感知与生成等核心单模态任务上,都表现出了极强的竞争力。LongCat-Flash-Omni 是行业内首个集“全模态覆盖、端到端架构、大参数量高效推理”于一身的开源大语言模型,首次在开源范围内实现了全模态能力与闭源模型的对标,同时依靠创新的架构设计和工程优化,使得大参数模型在多模态任务中也能达成毫秒级响应,了行业内推理延迟的难题。
LongCat-Flash-Omni 继承了该系列出色的文本基础能力,并且在多个领域都展现出领先的性能表现。和 LongCat-Flash 系列的早期版本相比,这款模型不仅没有出现文本能力的下降,反而在部分领域取得了性能上的进步。这样的结果不仅证明了我们训练策略的有效性,更突出了在全模态模型训练过程中不同模态之间所蕴含的协同价值。
图像理解方面:LongCat-Flash-Omni 的性能(在RealWorldQA数据集上得分为74.8分)和闭源全模态模型 Gemini-2.5-Pro 不相上下,并且比开源模型 Qwen3-Omni 表现更好;它在多图像任务上的优势特别突出,这主要是因为在高质量的交织图文、多图像以及视频数据集上进行训练所取得的成果。
音频能力方面,我们从自动语音识别(ASR)、文本转语音(TTS)以及语音续写这几个维度展开评估。在指令模型层面,其表现十分亮眼:ASR任务上,在LibriSpeech、AISHELL-1等数据集的测试结果优于Gemini-2.5-Pro;语音到文本翻译(S2TT)在CoVost2数据集上展现出强劲实力;音频理解任务中,在TUT2017、Nonspeech7k等任务上达到了当前最优水平;音频到文本对话在OpenAudioBench、VoiceBench上表现优异,实时音视频交互的评分与闭源模型接近,类人性指标更是胜过GPT-4o,成功实现了从基础能力到实用交互的高效转化。
视频理解方面,LongCat-Flash-Omni在视频到文本任务上的性能目前处于最优水平,其中短视频理解效果显著超过现有参评模型,长视频理解能力则可与Gemini-2.5-Pro和Qwen3-VL相媲美。这一出色表现主要得益于其采用的动态帧采样、分层令牌聚合的视频处理策略,以及高效骨干网络对长上下文的良好支持。
跨模态理解方面:性能超越Gemini-2.5-Flash(非思考模式),与Gemini-2.5-Pro(非思考模式)不相上下;特别是在真实世界音视频理解的WorldSense基准测试中,对比其他开源全模态模型呈现出明显的性能领先性,这一表现验证了其高效的多模态融合能力,使其成为目前综合能力处于领先地位的开源全模态模型。
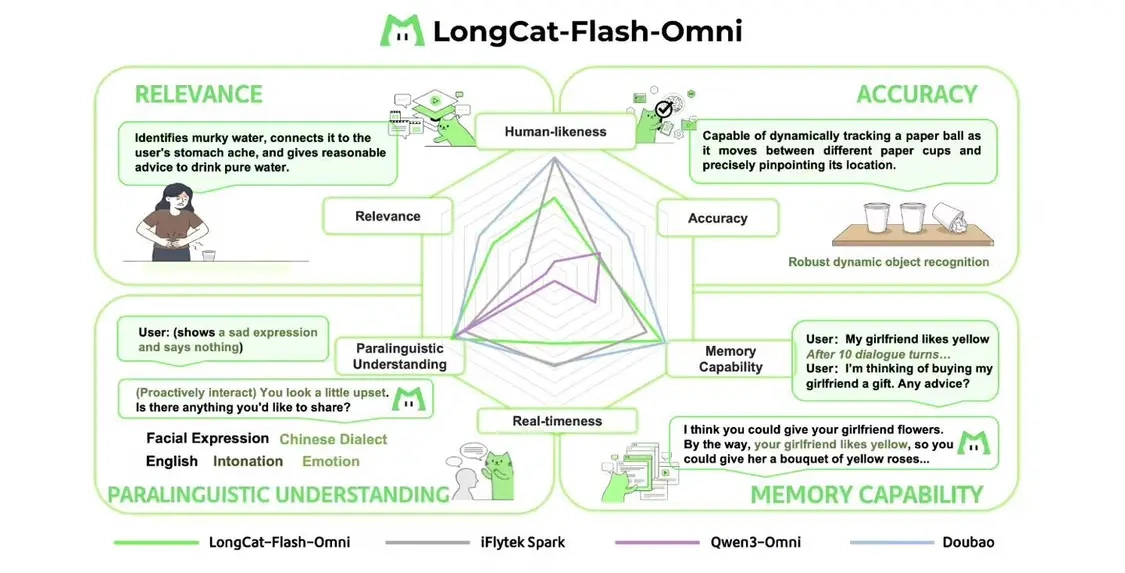
端到端交互表现方面,鉴于当下行业内缺乏成熟的实时多模态交互评估体系,LongCat团队针对性地搭建了一套专属的端到端评测方案。这套方案包含两部分:一是定量的用户评分(共250名用户参与评分),二是定性的专家分析(由10名专家对200个对话样本展开分析)。从定量结果来看,在端到端交互的自然度与流畅度维度上,LongCat-Flash-Omni在开源模型里优势明显,其评分比当前性能最优的开源模型Qwen3-Omni高出0.56分;而定性分析结果显示,LongCat-Flash-Omni在副语言理解、内容相关性以及记忆能力这三个维度上,已能与顶级模型相媲美,但在实时响应速度、交互类人性以及输出准确性这三个维度仍有提升空间,团队也计划在后续工作中对这些方面进行进一步优化。







